

Many terms circle AI. To build AI-intuition you need to internalize the first-tier terms in part 1. To gossip, muse and bore friends and family – head to part 2.
Modernity is ignorance.
We understand less of the things we use. Need fire? Who cares about spark, gas and plastic of a lighter. We do not lose sleep over CPU, batteries, glass, titanium, code and antenna when using a mobile phone.
We accept things as black boxes that “do their thing”. And dethrone magic into triviality.

AI is no different. It is a box that does its thing. It saves us time just like pocket calculators, GPS and airplanes. But it is still at its “magic” period. And like all magic – we tie crowns or sharpen wooden pegs.
This post is dedicated to looking behind the magician’s curtain (I will stop abusing this metaphor in a few lines). Yes – there are gazillion videos, articles and books on “how AI works”, and you can ask ChatGPT to explain it ״as to a sixth-grader״. But digging into the subject for a while – I find the challenge in knowing what to care about – and what not. There are so many terms. Some I find fundamental to building intuition for reviewing AI developments, and some less so.
Why Should We Care
“I also do not care about car solenoid”.
Valid point.
But cars are not the “téch-du-jour” (Tesla stock raises its hand in the crowd) or at least – do not have a veil of mystery and opportunity around them like AI does (Waymo taxi waves from the back).
Ok, ok. So it is not for everyone. Many (most) will be perfectly ok not knowing how things work. But for others – the ones that want to discuss tech news, speculate where opportunities, bubbles and hype is lurking – having a deeper understanding of the machine can help.
First – What do we mean when we say AI
AI is a piece of software.
An algorithm that when you feed something in one end – gives you a result on the other. It is not different from your pocket calculator (genius at math!) or the little “mind reading” line above your phone’s keyboard “predicting” the words you type (“Give me a sec” thanks the genius that placed the C and the X next to each other).
AI gets the “intelligence” label because of three peculiarities –
- The math used in building it is very complex – so much so that big parts of it cannot be explained in retrospect. We created a method that produces the correct answer – and we know how to do it again – but we cannot explain the steps to the solution. Sounds “mysterious” but other fields operate in similar ways (drug discovery, materials science) and even our intuition is not much different.
- When interacting with it – it feels we are talking to a person. This is caused by a combination of a “cheap trick” we will discuss later and a big word – Anthropomorphism. The big word is our tendency to see “human characteristics” in things even when there are none. Its cause is evolutionary (better at socializing) and it leads us to think there is intelligence in the machine (and see faces in clouds and Jesus’ face in a piece of cloth).
- It is good for many things. Unlike pocket calculators and GPS – AIs seem to “know” so much. It is hard to perceive that the knowledge out there (internet, databases, articles, images, books) can be used as a single “unit”. What AI does is make it available in a (much) more efficient way compared to search engines.
- It is a “language” calculator – and as we think in language (not in numbers or locations) – when we get answers in the form of our thoughts – it feels like the machine is “thinking” (see the big-word in reason #2).
Now that we know what AI is – let’s dive to what AI is made of and which parts matter to intuition-building.
First-tier Terms
[A word for the purists. What follows puts an emphasis on the ChatGPT/Gemini type of AI. The AI that is used for robotics, autonomous vehicles and pattern recognition is different and will not be discussed here]
Foundation Model and GPT
Foundation models are the heart and engine of what we refer to as AI. It is what the big companies spend mountains of money on and why NVIDIA stock went to infinity and beyond. It is the result of squeezing and mixing tons of written data, images, videos, voice, algorithms, math and manual human labor into lots of big computers and running them for a while. The outcome is a software that can predict how to complete what you ask. Notice the wording. “Complete what you ask”. Not “understand” and not even “answer”.
There are two things important to note –
- The foundation model is not “intelligent”. It only appears so because it is answering requests as if it understood what you meant and as if it has knowledge and abilities (there is a specific “trick” here that I will discuss below).
- The foundation model is “frozen in time and scope” – it “knows” the world only as much as the data it was fed with. If things happened after it was trained (Trump being elected or some other news or scientific recency) or if an edge-topic was not included (the suitability of the soil in your backyard to grow pineapples) – it will not be able to complete requests about it correctly. It does not mean it will not shamelessly try – which I will also discuss below.
The foundation models are using a bunch of different technologies to create text and images. When referring to text some call it Generative Pre-trained Transformer – or GPT for short. Generative for generating (text), Pre-trained – as I explained above – and Transformer – for the specific type of technology employed (will be mentioned in part 2).
There are few companies that make foundation models – GPT-4, DALL-E 3 (and Sora) by OpenAI, Gemini 1.5 Pro by Google, Claude 2 by Anthropic, Llama 2 by Facebook, Midjourney v5.2 by Midjourney and some others. The numbers (4, 4o, 3, 1.5, 5.2) and the superlatives (pro, nano, turbo) represent versions. It is as confusing as car models and actually means similar things – how fast, recent, economic and safe a model is. Unlike cars – new models are released every few months and usually improve in leaps. This is why the field is “in rapid development” and why if we stop seeing this (and there are good reasons why that might happen) – the time we live in will be referred to as “The Big AI Bubble” (not the first one but certainly the largest).
Multimodal and Diffusion
AI that creates text and AI that creates Images is (mostly) different. I will not go into details on how they work and only mention that “Diffusion” in the famous Stable Diffusion tool is what they (and OpenAI’s DALL-E) use as their tech for image generation. The idea behind it is to “train” the foundation model to clean noise from existing images (combined with the text describing them) and so teach the model to do the reverse – generate images from text.
These models too – do not “understand” or “see” anything.
When you type in ChatGPT or Gemini a request for an image or text, what happens behind the scenes is that the same chat box and same reply area operate on two different engines in the back. This is why they are called Multimodal.
[Multimodal and not Multi-model because they fuse information from multiple sources – multiple modalities. You will not be wrong calling them multi-model, but considered less cool.]
Fine-Tuning
If you have a question in the lines of “in which legal proceedings in the 1970s did the precedent of the Cohen vs Kramer 1952 Ohio ruling hurt the case of the defendant” The foundation model might have problems generating an answer. The reason is that the data it was trained on did not include minor legal cases from Ohio nor the use of precedents in 1970s. To answer questions like this – the foundation model needs to be “fed” with more data – in this case – all the relevant cases.
This is called “fine-tuning” – it is taking an already able model (that can generate good language and has good “knowledge” of the world) – and making it more “knowledgeable” in edge-topics.
Not all foundation models allow fine-tuning to be done on them. The ones that do are often open-source that can be installed and then “manipulated” to make them better at edge cases.
Why is this important and not a minor technical thing under the hood? Because many companies are raving about building “AI for farm vets that ChatGPT knows nothing about!”. However, much of the fine-tuning – making a model better at something that is in its core (knowing the world, not making mistakes, not being biased, having better reasoning) – is what the makers of the models constantly strive for. Only with deeper pockets. So if GPT-3 was a so-so expert, GPT-4 is better and GPT-5 will be able to tell you how rumen buffers affect digestion of Polish Holstein-Friesian cows compared to the Dutch Lakenvelder.
Training Cut-off, Search and RAG
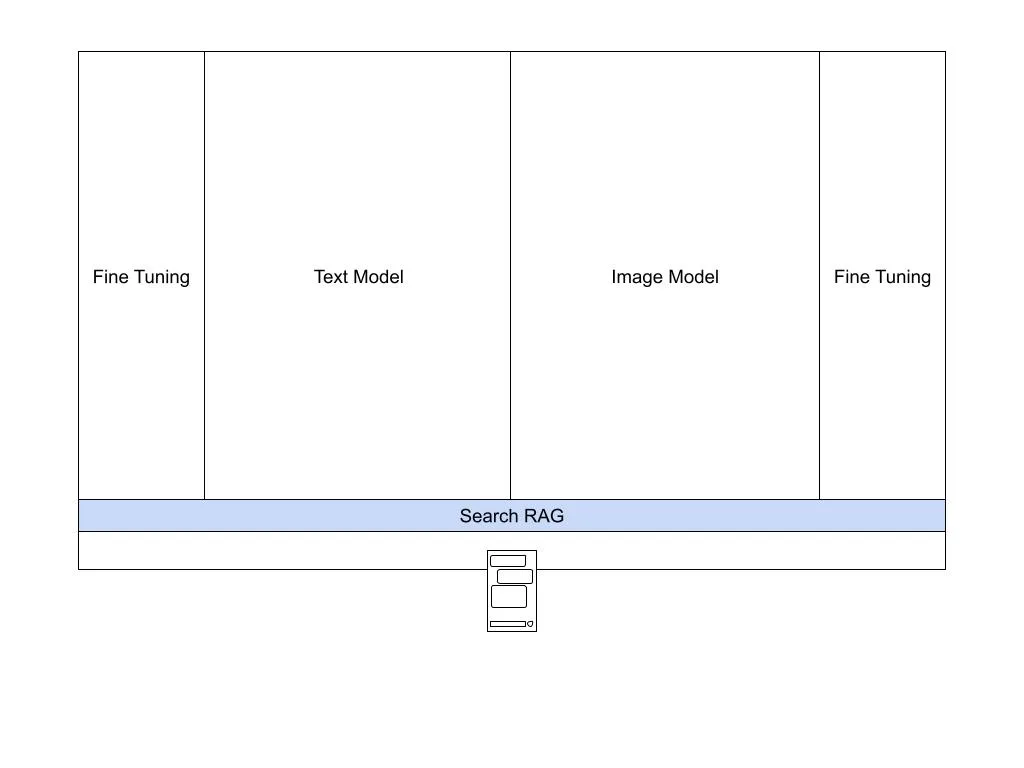
As mentioned above, the foundation models are trained up to a specific point in time. They are not “continuously” trained because the technology doesn’t work this way (for now) and when fed with “all the data” – it takes them time to “digest” and turn into an able model (plus, it is super-expensive). GPT-4 has an official “Knowledge Cut-off Date” at September 2021 (unofficial estimates give a more recent April 2023) while Gemini is estimated (no official date provided) to have cut-off at mid 2023.
This is problematic if you want help with recent knowledge. “Who won the presidential election in 2024” is something it simply “does not know” as it is not part of the data it was trained on. Not only news but also recent knowledge is missing. You will not be able to find the research proving your sweet tooth is genetic so out of control as you suspected.
How do AI tools overcome this problem? They connect the foundation model to the internet. They add good-old search to the mix. So if you ask it about the elections – it will “understand” this is recent – will conduct a quick search and will feed the results to the model – to generate an easy to consume reply (it is great in generating text, remember?).
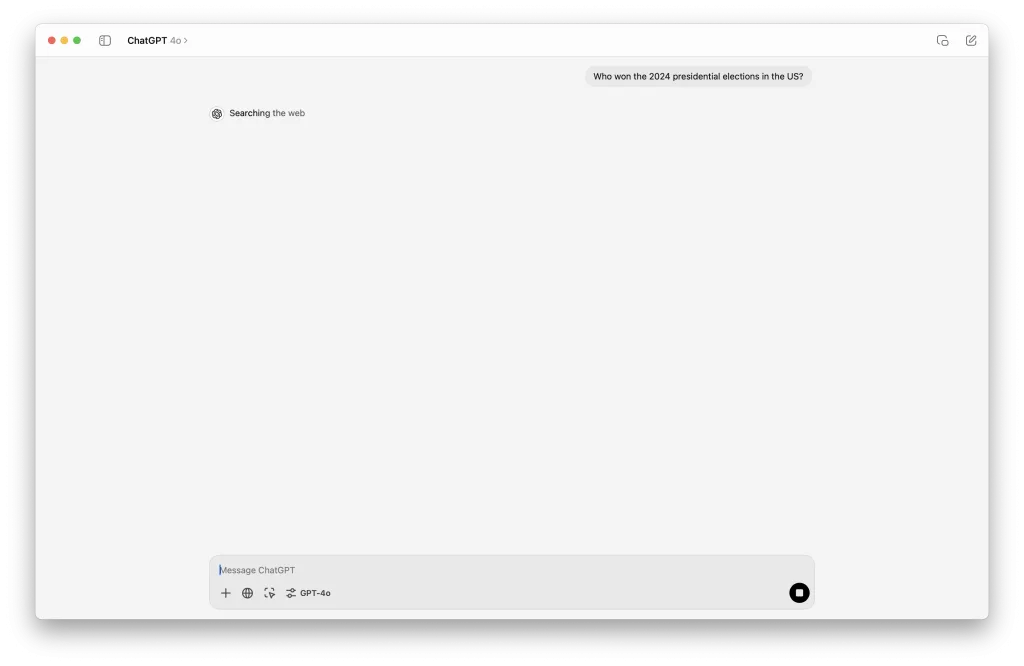
This technology is called RAG – Retrieval Augmented Generation. It is important because what it allows doing is adding to the foundation model data it was not exposed to (not trained on) and still get value from its core super-capabilities.
Instruction Tuning, Chat and UI
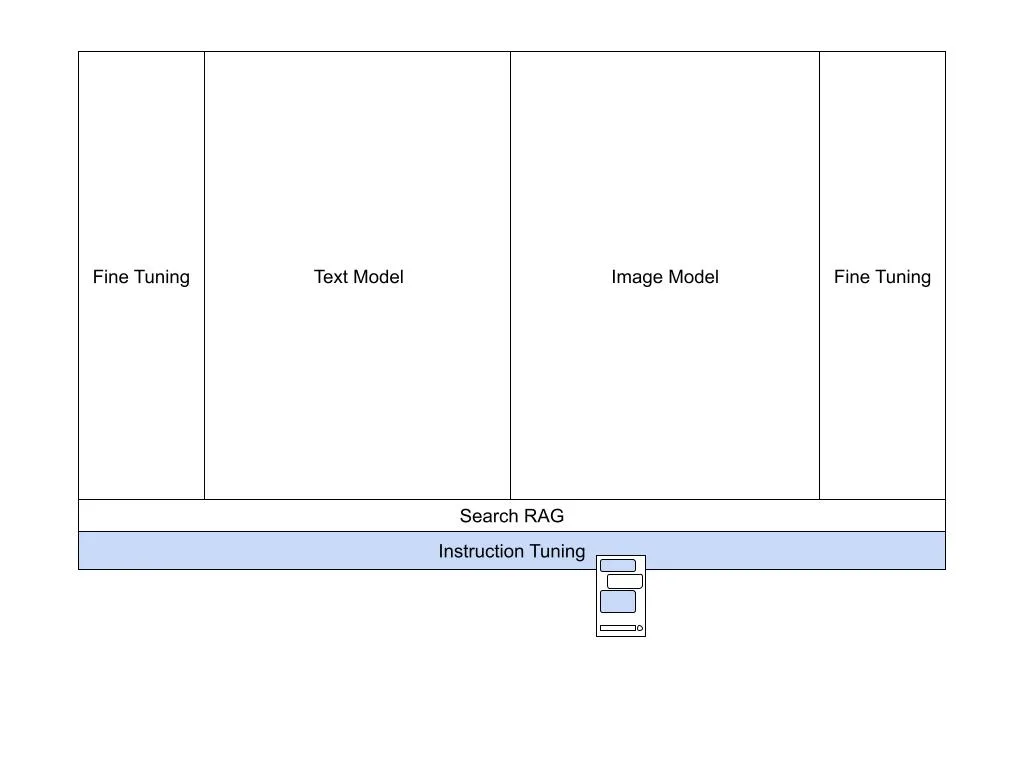
Remember the fancy word Anthropomorphism? The tendency to attribute “human” traits to everywhere showing a hint of being a person? One of the main reasons we attribute “intelligence” to a foundation model is something called instruction tuning.
Instruction tuning, similar to fine-tuning, is done “on top” of the foundation model. It is taking lots of questions and answers and feeding them to the model so when it will get a question – it will “know” what is the most suitable way to reply. Not only the relevant “completion” but also how to “phrase” it – so it sounds best to a human.
This is why we get “You are absolutely right!” when we reply something doesn’t sound correct and “Let me know if there’s anything else you’d like to include or modify.”
Without instruction tuning there would only be GPT (open source and non-profit) and no ChatGPT (and Elon Musk would not sue the company he funded).
The Chat is of major importance. It allows user-friendly interaction with the very-technical foundation model (and its RAGs). It is the UI layer.
Other UI layers make the foundation model (or a few coupled into multimodal) useful for different use cases. For example, if you do research you might want to collect a few sources and then run the foundation model magic on them. It is not comfortable in traditional chat, so companies like Google wrap the core abilities in different UI – such as what they do in NotebookLM.
Prompt, Size and Engineering
When you ask something from the AI “chat” it is called a “prompt”. I put “chat” in quotes, since you are not really “chatting” with anything. When you write text, the foundation model (with the help of a RAG if needed) completes the prompt and wraps the response with words that make you feel as if a human understood and replied (using the instruction tuning). It is also visually arranged in a way that looks like a chat response – making it easier for humans to “consume” as something they are already familiar with.
The size of the prompt is limited. If you send a very large text (can also be documents you uploaded or context – which we will discuss in a minute) the quality of the response will deteriorate. It is simply beyond what the foundation model was trained to reference or digest. Where things are now – the prompt can be at a length of about 100,000 words (about the size of a Harry Potter book). Sounds like a lot. But quality drops as size grows. You can say the model is “losing concentration” (not a technical term, but a good metaphor).
Prompting also helps the model locate the right “area” to give an answer from. It is similar to Google’s search – you can search for Apple – and the engine might be “confused” to which apple you refer to – the company or the fruit. Helping the model by prompting “full” questions (“Please answer as if you were a professional nutritionist”) helps it return better responses.
As Google became better over the years with “guessing” what you mean (Apple or apple) so do the foundation models. You will need to be less an “expert prompter” to get quality replies. On the other hand – to get unique replies (styled text, code, graphs, specific images) – users need to be as specific as possible when prompting. It is called Prompt Engineering. Akin to being a good driver for getting the most out of a vehicle.
Session, Context Carryover and Memory
On the side of the chat user interface – you usually find a list of “Conversations”. They are actually “sessions”. If you are familiar with this term from browser technology – it is similar (do not worry if you are not). Each one of them is a back and forth “dialogue” with the foundation models which creates sort of an extended “prompt”. What it means is that when you are in the “session” – you can refer to things you discussed with the model earlier. It is a good way to refine your prompt if the reply you got was not what you expected. But here also lays the session downside – if you continue chatting in the same session – the model might get both confused and eventually overwhelmed by where the conversation is going.
The user interface helps prevent it. Every time you open a service/app – it usually starts from a new session. You will have to deliberately go back to a previous session in order to continue a conversation with context to previous topics. This is context carryover. It is powerful – but limited.
Different people prefer different styles of response and have different underlaying prerequisites. And they would prefer not to “remind” the AI in each session about them. People want the AI to remember them.
Furthermore – people might want the AI to get to know them personally (though no Scarlett Johansson breaking your heart available just yet).
The first wish – remembering things about you between sessions – is called “memory” in ChatGPT, “Gems” in Gemini and “Cache” in Claude (each works a little different but they are similar). They store things the engine deems “important” (you can look inside memory in ChatGPT and see/control what it remembers. It can be rather amusing). These tid-bits are added to the prompt (behind the scenes) and are supposed to make the replies more personal.
The second wish – intimate knowledge of who you are – is yet to be realized.
Google and Apple are busy integrating their AI to the assets they already have – email, calendar, messaging, photos. The personalization they will produce from this integration is slightly different from memory. It is generating or finding “context” to enrich or create prompts where the AI is being operated – documents, emails, conversations etc.
Integrations (term under construction)
The AI ability to “communicate” with external systems is referred to as “integrations”. It is what Gemini and Apple Intelligence most pride themselves about and is what ChatGPT Work with Apps and Claude’s Computer Use strive to do. Integrations is not an official term for it, and it is still early days (these abilities work better in demos than in real-life). What they basically do is pull or inject text/images to and from other applications – either from the response of the foundation models or into the prompt. It is not new technology per se – it is more of a UI thing. Easier use (less copy and paste) generates more utility.
Agency
If the AI is so smart – why can’t it do things without me asking?
Because it is not smart. It is completing your requests. You start a sentence (prompt) and it finds the best way to complete it (reply). It has no “motivation” and no “preference” and no ability to start a conversation or take action by itself. Exactly as Google does not start a search for you.
Taking initiative is called “agency”.
The major AIs (ChatGPT, Gemini etc) do not have agency. Autonomous cars (and AI NPCs) – debatable – but I would say yes.
In an interesting turn of events, the “regular” AIs – the ones that create really good text – create really good code as well. Code runs on computers, and computers can be good agents (do things without being ask explicitly). So the road to agency is in sight.
That’s it.
These are the terms worth internalizing to build an intuition for AI in the near future.
If you want to dive a bit dipper – head to part 2.
4 responses to “Building AI Intuition Through Terminology [Part 1 of 2]”
[…] The many terms of AI, part 2. What you need to internalize for gossip, musing about the future and talking-shop. Want the intuition-forming basics? Re-read part 1. […]
[…] The many terms of AI, part 2. What you need to internalize for gossip, musing about the future and talking-shop. Want the intuition-forming basics? Re-read part 1. […]
[…] this sounds familiar from a recent article you read about AI, it might not be a coincidence. There are similarities between a “trained […]
[…] this sounds familiar from a recent article you read about AI, it might not be a coincidence. There are similarities between a “trained AI […]